Level up your React codebase quality

In the ever-evolving world of web development, React has firmly established itself as a dominant force. Its component-based architecture, rich ecosystem, and performance optimisations make it a preferred choice for building dynamic and interactive web applications.
However, as projects grow in size and complexity, maintaining high code quality in React codebases becomes increasingly challenging.
In this blog post, we will explore strategies and best practices for improving code quality in React applications. Whether you're a seasoned React developer or just getting started, you'll find valuable insights to elevate your codebase and streamline your development process.
Pure components
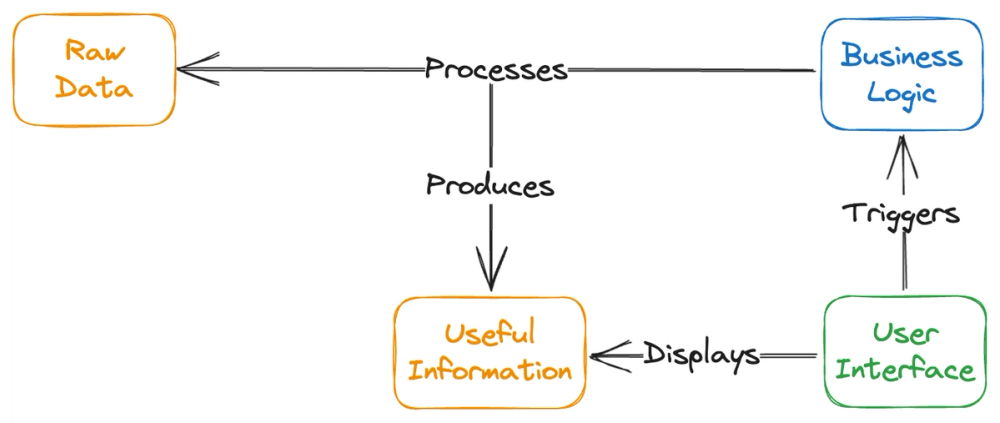
When developing web applications, developers need to think about the user interface as just another representation of the data flowing through the system. Composition is the main principle of React, and at the end of the day, a JSX representation of the data is no different than JSON or YAML.

Separating the UI into visual components and business logic is beneficial to React codebases because it allows for better organisation, clearer reasoning and maintainability of the code. Everything is logically grouped, inter-dependencies are brought to a minimum, and modifying or adding a feature happens smoothly and without the need for out-of-scope refactoring.
In addition, your code’s reusability increases. Your logic-less UI components can be packed in an npm package and be used for a new project, accelerating its development and providing a seamless experience across the business products. With recent technology, like React Server Components, your business logic can also be packaged and reused across projects to increase the speed of delivery.
Another area that benefits from this approach is testing. When UI components have business logic mixed in, unit tests increase in complexity - they require specialised UI testing libraries to mimic user interactions, following specific paths around the business logic. In contrast, when the business logic is decoupled from the UI components, your unit tests are more focused - the UI tests are data-driven, meaning that we only need to check the UI matches the expected layout based on the data we provide to our component and that the expected user interactions trigger the relevant events.
By adopting pure components, you can also integrate visual regression testing into our projects with ease. As the name implies, visual regression testing checks the components in your project and reports any visual regressions it can find via snapshot diffing. In a project that does not separate UI from business logic, visual testing is not straightforward and usually requires heavy data and interaction mocking.
Lastly, separating UI and business logic can improve the overall performance of the application by reducing the amount of unnecessary re-rendering that can occur when a lot of business logic runs in the same component. The smaller units make it easy for developers to spot performance issues and heavily optimise only the areas that show them.
Custom hooks
Since their introduction in 2018, React hooks have become a first-class citizen of React applications. In hindsight, this was to be expected: React hooks are functions, and functions are first-class citizens of JavaScript. This makes hooks one of the main tools in React, a UI library built on functional programming principles.
For me, React hooks helped consolidate the functional nature of React, and they have been the perfect replacement for the old OOP patterns used in React applications.
To understand it better, let’s compare hooks with a Javascript class:
| React Hook | React Class | |
|---|---|---|
| State | Declared using React.useState | Declared in the class or via this.state |
| Actions | Anything can be returned by the hook, including state and actions that update the internal state | Declared as class methods, and only visible to the same class. Logic can be extracted in a util file for external use |
| Reusability | A hook can be used however many times and in however many components | A class component’s internal logic cannot be reused in other components |
With these 3 mechanisms available, hooks offered a new pattern that continues to help engineers develop highly maintainable applications that work great for their users.
Generally, any business logic used by a React component can be extracted in custom hooks that can be shared by different parts of the codebase, even by different applications.
A rule of thumb to follow when extracting business logic from React components is to use the use keyword in a function name, thus making it a React hook, only if the function uses React hooks internally.
Predicate functions
Predicate functions are pure functions that return a boolean value, providing some useful information about the arguments.
The most common use case of a predicate function is in the Array.filter method. It iterates over an array, running the provided argument function (the predicate) with each of its elements as argument, and returns another array, containing only the elements for which the predicate returned true.
const numbers = [10, 4, 9, 2, 0];
numbers.filter(element => return element < 5);
// [4, 2, 0]
You probably stumbled across code that used the filter method, and had to have more than a glance at it to understand its logic.
Let’s take an example:
function getHomescreenPlaces() {
const areaOfInterest = getAreaOfInterest()
const places = getPlacesFromDB();
return places.filter(place =>
place.workHours.start <= '12:00' &&
place.workHours.end >= '18:00' &&
place.bounds.x1 >= areaOfInterest.x1 &&
place.bounds.y1 >= areaOfInterest.y1 &&
place.bounds.x2 <= areaOfInterest.x2 &&
place.bounds.y2 <= areaOfInterest.y2
);
}
You might be able to figure out what the filter function does, but I think anyone can agree that this function is a code smell. How could we do better?
const shouldShowOnHomescreen = (place, areaOfInterest) => {
return place.workHours.start <= '12:00' &&
place.workHours.end >= '18:00' &&
place.bounds.x1 >= areaOfInterest.x1 &&
place.bounds.y1 >= areaOfInterest.y1 &&
place.bounds.x2 <= areaOfInterest.x2 &&
place.bounds.y2 <= areaOfInterest.y2;
};
function getHomescreenPlaces() {
const areaOfInterest = getAreaOfInterest()
const places = getPlacesFromDB();
return places.filter(place => shouldShowOnHomescreen(place, areaOfInterest));
}
This is a bit better, but the name isValidPlace does not communicate anything about the way the filter acts. Let’s try again, but at a finer grain:
const isInAreaOfInterest = (place, areaOfInterest) => {
return place.bounds.x1 >= areaOfInterest.x1 &&
place.bounds.y1 >= areaOfInterest.y1 &&
place.bounds.x2 <= areaOfInterest.x2 &&
place.bounds.y2 <= areaOfInterest.y2;
};
const isOpenInAfternoon = (place) => {
return place.workHours.start <= '12:00' &&
place.workHours.end >= '18:00';
};
function getHomescreenPlaces() {
const areaOfInterest = getAreaOfInterest()
const places = getPlacesFromDB();
return places.filter(place =>
isInAreaOfInterest(place, areaOfInterest) &&
isOpenInAfternoon(place)
);
}
Now this is easier to read - we are only looking for places that are inside our area of interest, and that are open in the afternoon.
The isInAreaOfInterest and isOpenInAfternoon methods are pure and can be easily tested and reused.
Predicate functions don’t need to be used only with the filter method. They should be used everywhere across the codebase when checking for a business-specific attribute on your data. In fact, a best practice to improve code readability is to replace most of the places where boolean logic is used, with predicate functions.
Prefer derived values to synchronised state
Note: Kent C Dodds has a great article on this topic. Make sure to check it out!
This is a pattern that is unfortunately common seen in many codebases:
function MyComponent({ prop1, prop2 }) {
const [aggregatedData, setAggregatedData] = useState();
useEffect(() => {
const someResult = calculateResult(prop1, prop2);
setAggregatedData(someResult);
}, [prop1, prop2]);
return (
<ChildComponent data={aggregatedData} />
);
}
In this example:
- we receive two props in a component
- we apply our business logic in
useEffectto calculate a result, which is then stored as component state viauseState - we give the stored result to a child component as a prop
Here, using useEffect and useState to compute the data is unnecessary and it will, in many cases, degrade the performance of our component. The same result, but without a performance impact, can be achieved by simply removing the hook calls:
function MySimplerComponent({ prop1, prop2 }) {
const aggregatedData = calculateResult(prop1, prop2);
return (
<ChildComponent data={aggregatedData} />
);
}
Unless our calculateResult method does costly processing when run, the hook-less variant is preferred, as it’s clean and easy to debug.
When calculateResult is does heavy processing, we can use the useMemo hook to memoize its results and reduce its potential performance impact during a re-render.
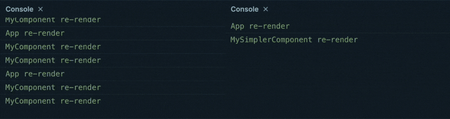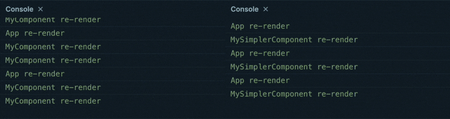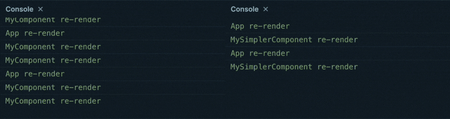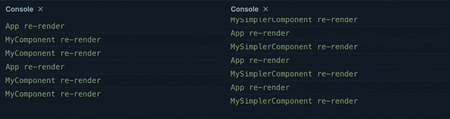
To understand better how this works, let’s take a look at what happens in both situations when the component is re-rendered.
Firstly, let’s describe the process it takes MyComponent to display an update:
- React renders
MyComponentby calling our defined function with its props - The component instructions are run step by step:
- we call
useState→ React finds the component state in its hooks “cache” and returns the current valueaggregatedDataand its settersetAggregatedData - we call
useEffect→ React compares the current values ofprop1andprop2, then it executes the associated function (effect):- call
calculateResult - call
setAggregatedData, which enqueues a component re-render with its updated state
- call
- we return the resulting virtual DOM for the component
- we call
- React compares the current DOM of
MyComponentwith the new DOM (not containing the updated state), and since the state is not updated until the next enqueued re-render, they are likely identical and the result is discarded, not resulting in a DOM update - The enqueued re-render is executed:
- we call
useState→ React finds the new component state in its hooks “cache” and returns the current valueaggregatedDataand its settersetAggregatedData - we call
useEffect→ React compares the current values ofprop1andprop2, and because we just had a re-render and they are identical, the effect is skipped - we return the resulting virtual DOM for the component using the new value of
aggregatedData
- we call
- Finally, React compares the old and new component virtual DOM once again, and updates the browser DOM with the new version
Now let’s describe same process for MySimplerComponent:
- React renders
MySimplerComponentby calling our defined function with its props - The component instructions are run step by step:
- We call
calculateResult, then return the resulting virtual DOM for the component - we return the resulting virtual DOM for the component using the result of
calculateResult
- We call
- React compares the current DOM of
MySimplerComponentwith the new DOM (containing the updated result ocalculateResult), and updates the browser DOM with the new version
You can easily see why using useState and useEffect can impact a components’ performance. There is a clear overhead in the hooks approach, which not only introduces more operations during a re-render, but also causes a second re-render of the component.
You can test this behaviour yourself in this example playground.
Elevating the code quality in your React codebases is not just a matter of following best practices but also an ongoing commitment to maintaining a well-structured and maintainable codebase.
By adhering to the principles and techniques outlined in this blog post, you'll be better equipped to tackle the challenges of complex projects, collaborate effectively with your team, and ensure your React applications remain robust, scalable, and adaptable in the face of changing requirements.
Remember that code quality is a continuous journey, and every improvement you make brings you closer to a more efficient and enjoyable development experience.
Put these strategies into practice, keep learning, and watch your React projects thrive. Happy coding!




